Вопрос:
Когда я использую метод pandas value_count, я получаю следующие данные:
new_df[‘mark’].value_counts() 1 1349110 2 1606640 3 175629 4 790062 5 330978
Как я могу получить процент для каждой строки, как это?
1 1349110 31.7% 2 1606640 37.8% 3 175629 4.1% 4 790062 18.6% 5 330978 7.8%
Мне нужно разделить каждую строку на сумму этих данных.
Лучший ответ:np.random.seed([3,1415]) s = pd.Series(np.random.choice(list(‘ABCDEFGHIJ’), 1000, p=np.arange(1, 11) / 55.)) s.value_counts() I 176 J 167 H 136 F 128 G 111 E 85 D 83 C 52 B 38 A 24 dtype: int64
В процентах
s.value_counts(normalize=True) I 0.176 J 0.167 H 0.136 F 0.128 G 0.111 E 0.085 D 0.083 C 0.052 B 0.038 A 0.024 dtype: float64
Per @jezreal предложение
counts = s.value_counts() percent = s.value_counts(normalize=True) .mul(100).round(1).astype(str) + ‘%’ pd.DataFrame({‘counts’: counts, ‘per’: percent})
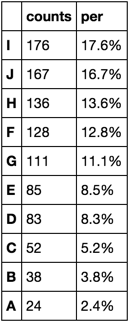
Ответ №1
Думаю, вам нужно:
#if output is Series, convert it to DataFrame df = df.rename(‘a’).to_frame() df[‘per’] = (df.a * 100 / df.a.sum()).round(1).astype(str) + ‘%’ print (df) a per 1 1349110 31.7% 2 1606640 37.8% 3 175629 4.1% 4 790062 18.6% 5 330978 7.8%
Сроки:
Кажется, что быстрее используется sum использования в два раза value_counts:
In [184]: %timeit (jez(s)) 10 loops, best of 3: 38.9 ms per loop In [185]: %timeit (pir(s)) 10 loops, best of 3: 76 ms per loop
Код для таймингов:
np.random.seed([3,1415]) s = pd.Series(np.random.choice(list(‘ABCDEFGHIJ’), 1000, p=np.arange(1, 11) / 55.)) s = pd.concat([s]*1000)#.reset_index(drop=True) def jez(s): df = s.value_counts() df = df.rename(‘a’).to_frame() df[‘per’] = (df.a * 100 / df.a.sum()).round(1).astype(str) + ‘%’ return df def pir(s): return pd.DataFrame({‘a’:s.value_counts(), ‘per’:s.value_counts(normalize=True).mul(100).round(1).astype(str) + ‘%’}) print (jez(s)) print (pir(s))

